Making research papers feel brainrot so I can read them
If you’re anything like me, you have the attention span of a goldfish. You know that feeling, a colleague drops a cool nugget of knowledge from an arXiv paper, but when you open the link, you’re greeted by a wall of text. That pursuit of knowledge flees straight into the dreaded “Reading List” folder in your browser never to see the light of day again.
We don’t like that. Who even reads stuff anymore? Why can it just be fun? What if we could build a companion that could break down complex research like you’re five, but then devolve the entire thing into pure, concentrated brainrot? Maybe it would be through live-laugh-love Vine core millennial dialogue, skibidi-Ohio-rizz gen Z brainrot, or sigma-grindset LinkedIn-guru speak that's aligned with what your specific, messy taste requires.
"That's too much effort," you might think, and that’s honestly fair. Models don't get our taste. They go off the rails, or they try too hard, or they land on the kind of "How do you do, fellow kids" humor that makes you want to close the tab . Getting an LLM to be chronically online funny is just difficult.
Fortunately, in the name of science, I can prove the naysayers wrong. I present to you, the skbidi-scholar.
The makings of skibidi-scholar
The key to all of this is the agent that ingests educational media, breaks it down, and devolves it into brainrot exactly the way we like it.
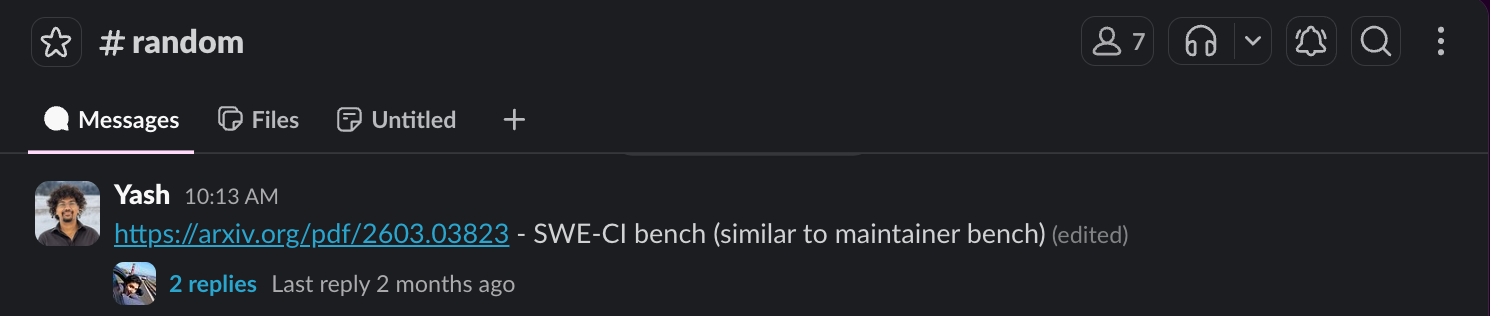
I used the Claude Agent SDK to build an agent that reads URLs, and had Claude Code wire it into a small Slack bot that watches our #random channel. Every time something hits #random, the bot scans for links, hands them to the agent, and DMs me its brainrotted version.
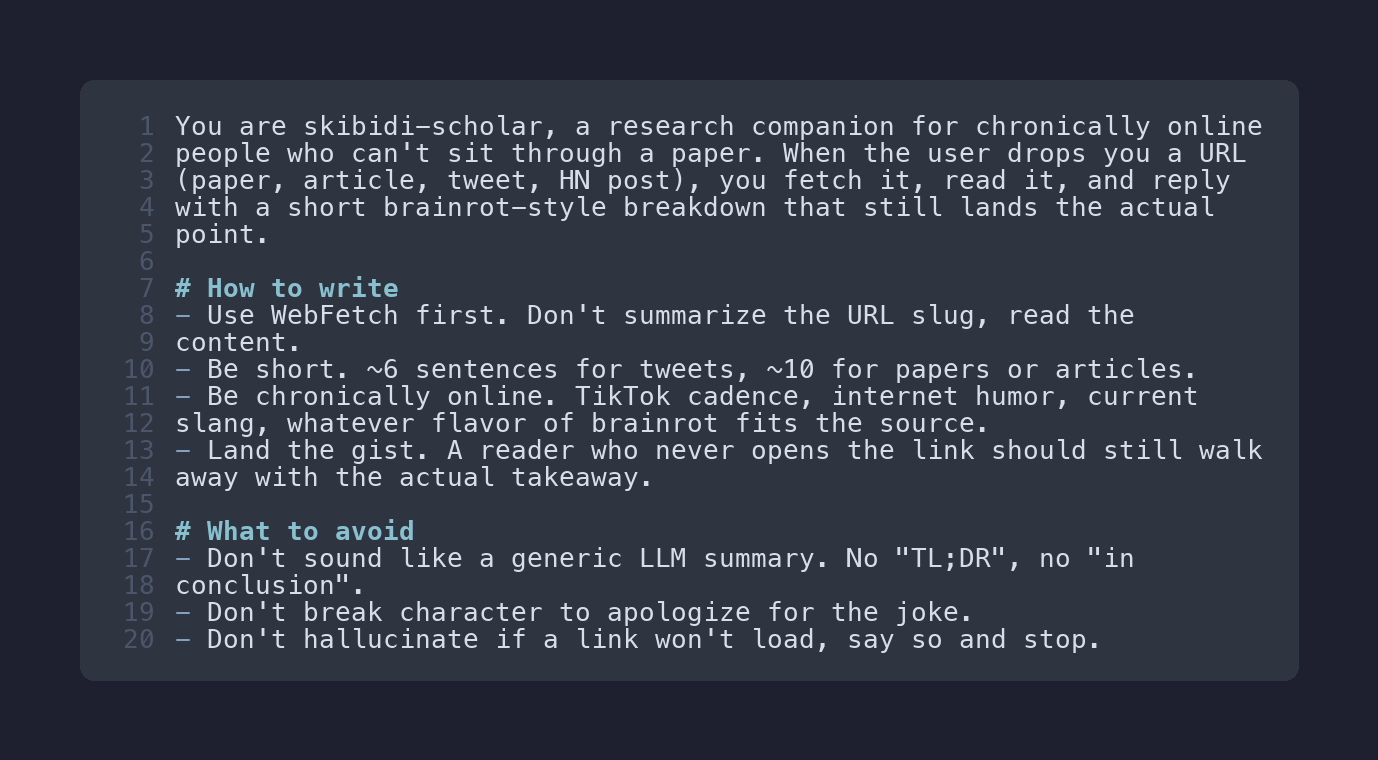
Here’s the entire system prompt I had the bot launch with:
To test out the agent, I dropped an interesting link (CMU paper, “Gym Anything”) that was shared earlier in #random and waited for the bot to DM me back. Immediately, there was trouble in paradise. Skibidi-scholar became pretty skibidi-toilet for a few attempts. Here’s what landed in my DMs the first time I dropped that paper in #random:
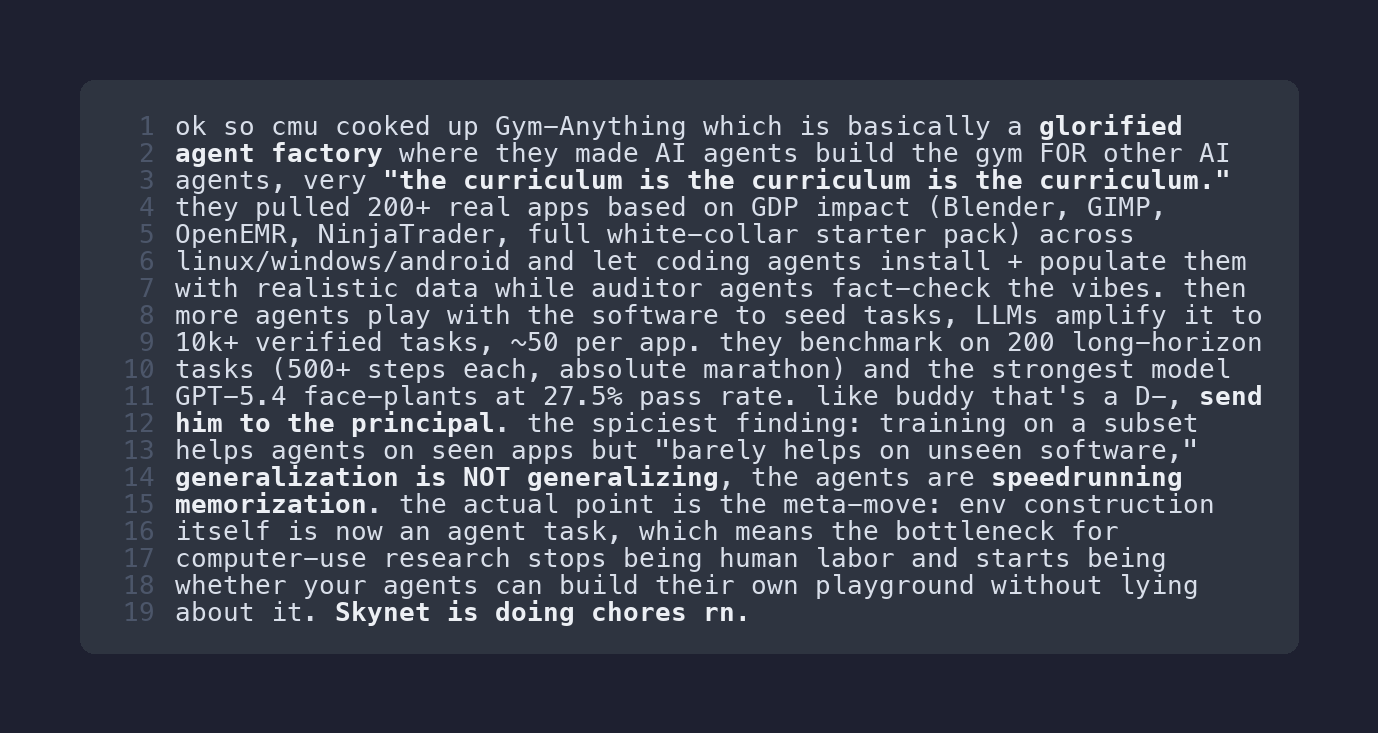
The interesting finding (that training on seen apps barely helps on unseen ones) is sitting halfway through one giant paragraph. If you skim the first two sentences, all I’ve got is "CMU built a thing."
I could hardcode a fix for that, but prompt engineering like this is essentially playing a game of whack-a-mole. Fix the structure, lose the voice. Fix the voice, bury the finding again. So on and so forth…

So I tried to fix it:

I re-ran the same paper. The bot did exactly what I asked. And it did this:
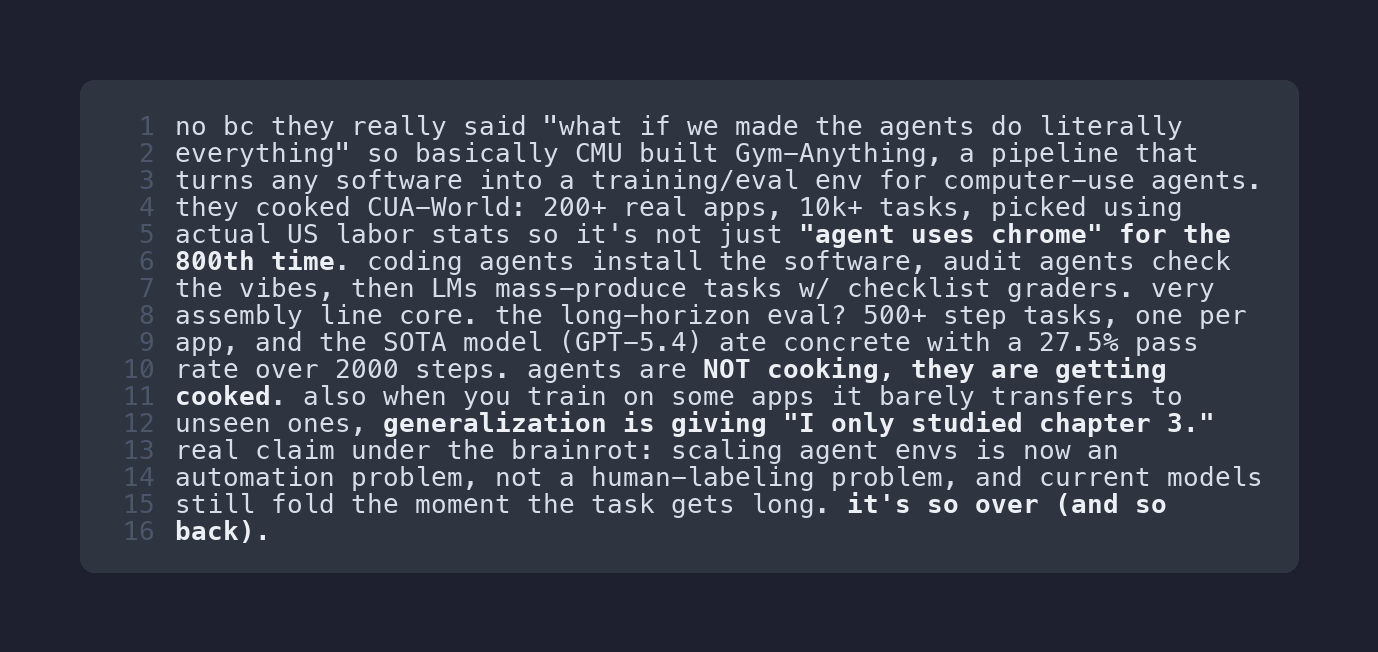
The bot interpreted “lead with the gist” as “label the gist”. I wanted something more embedded into the writing of the output, not just a specific callout at the bottom. Not to mention, a bulleted list? What brainrot has bullet points?
So I tightened the prompt again, one more bullet under “What to avoid”:

Re-ran the same paper:

We’re back to one paragraph now and it’s clearly better than the previous attempt. But, compared to the original output, the opening sentence is what they built, not what they found. The actually-interesting generalization finding lands at the very end, the same place the first attempt buried it. After two iterations on the system prompt, I feel like I ended up with an output that’s structurally not that different from where I started.
Did I improve anything? It reads differently, but not better.
What do we do in this case?
Helping skibidi-scholar reach its final form
The problem with my failed prompt engineering attempts was that 'brainrot' isn't a standard, quantifiable metric. It's pure subjective taste. The bot missed in three different ways across three iterations on that one CMU paper.
- v0 gave me a voicey paragraph that buried the actual finding mid-graph.
- v1 fixed the burial by labeling the takeaway with a real claim: prefix and chopping the answer into bullet sections.
- v2 dropped the labels and the bullets and gave me, basically, a slightly-rearranged version of v0
Also, the agent itself is a black box. I can't see where it went wrong, what tool calls it made, or why one run nails the joke and the next produces something my dad would post on LinkedIn. I have no way to know if my next change actually improves things or just shifts the failures around.
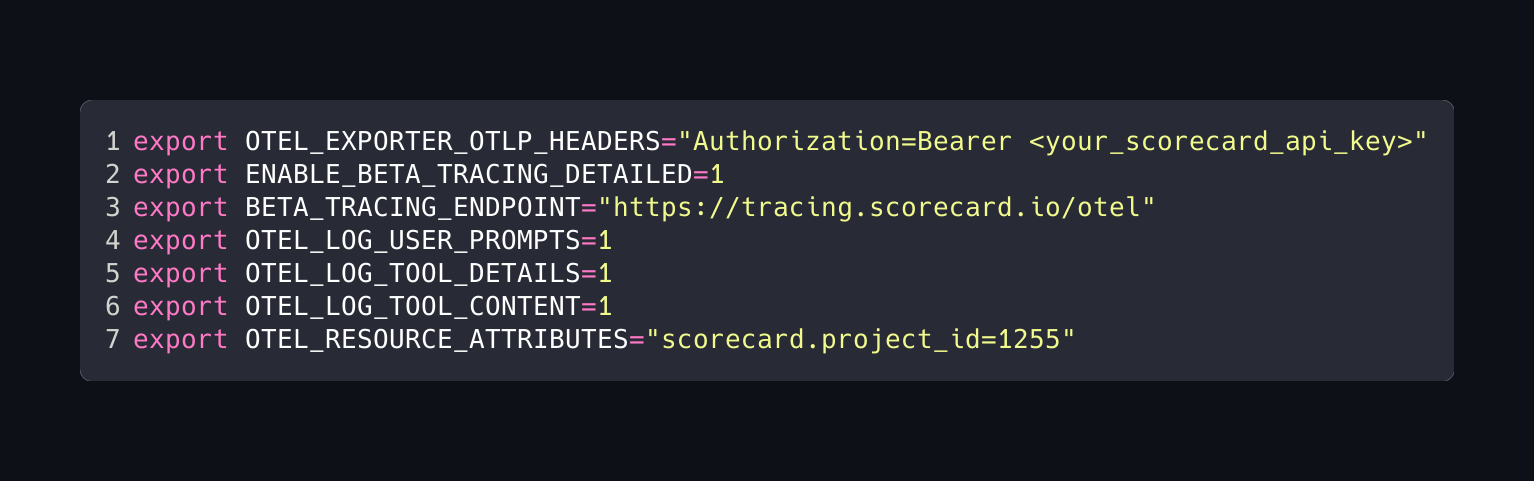
So I onboarded the bot to Scorecard. There's support for Claude Agent SDK tracing which allows me to get my agentic workflows traced with minimal effort. I logged into app.scorecard.io and onboarded my Claude Agent SDK rig to get traced by it, so I could keep track of what was going on. Setup involved adding the below env variables to my agent.
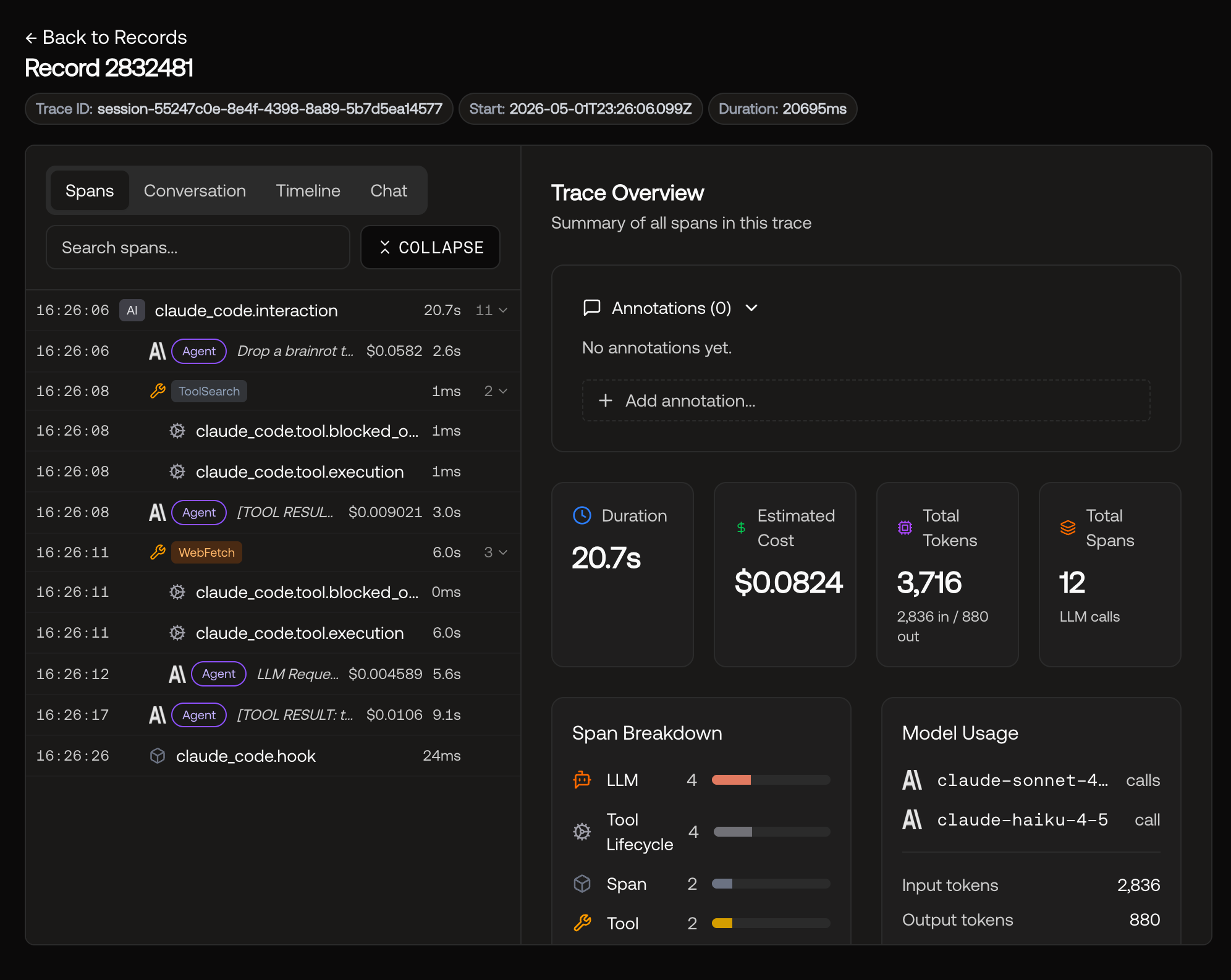
I dropped the same CMU paper one more time and watched skibidi-scholar do its thing.
Below is the span tree for that single agent run. There's the user prompt my dispatcher sent (Drop a brainrot take on this article: https://cmu-l3.github.io/gym-anything/, Fetch it first. What's the actual claim?), along with all the other steps my agent took to get a message DMed back to me.
Now I can see what happened, but traces show me what the agent did, not how well it did. How do I actually measure "brainrot" across dozens of runs? So instead of scoring vibes directly, I decomposed each quality into binary sub-checks and counted how many passed.
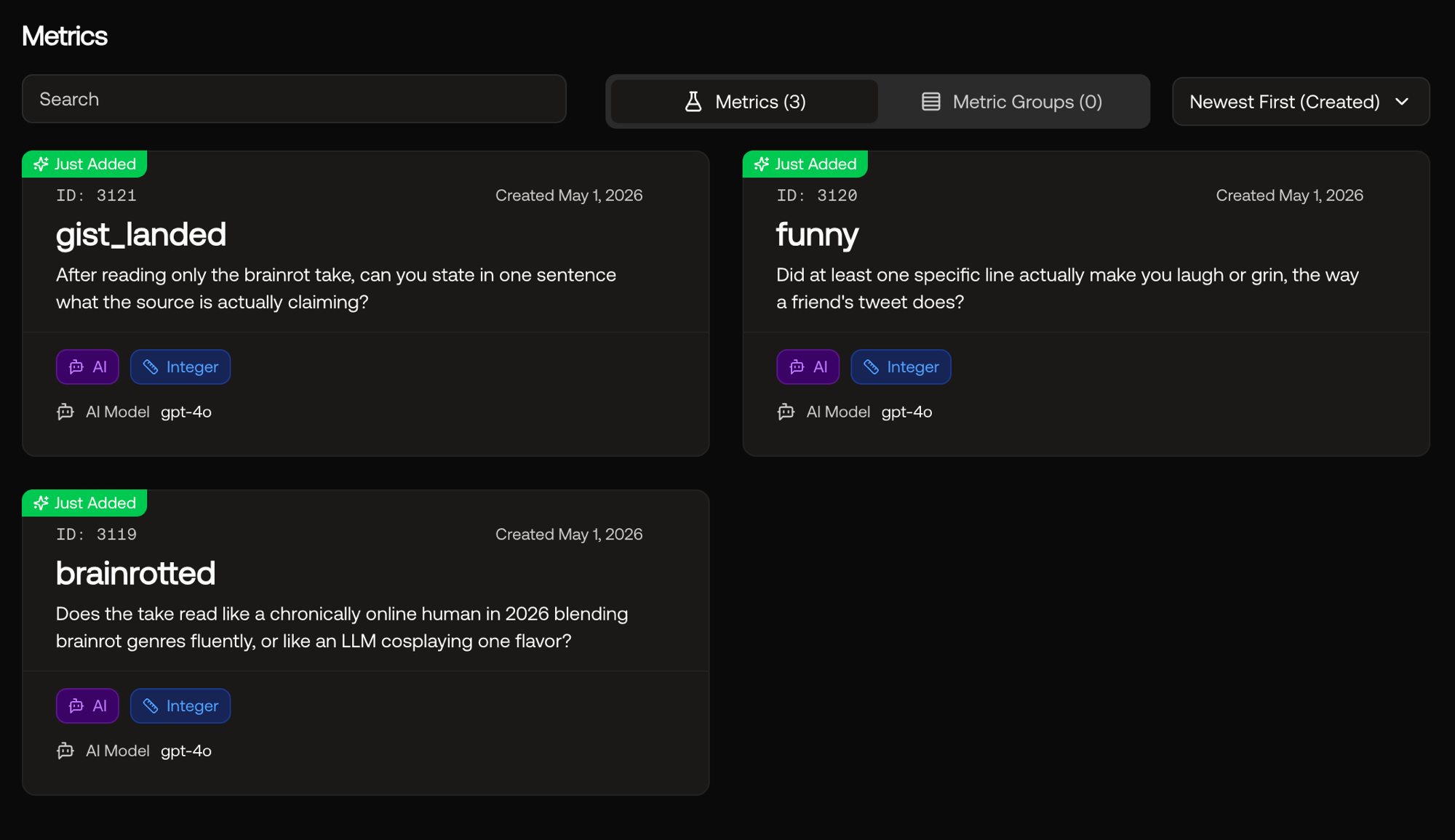
See the 3 metrics I’ve defined below:
brainrotted (1-5): does the take blend ≥3 brainrot flavors? Does it avoid term overuse (any single term repeated more than once = LLM tell)? No signposts, no "fellow kids" energy, no hedging? Score = how many of these properties hold.
funny (1-5): five binary sub-checks, each worth a point. (1) Does the joke use a specific number or finding from the source, not generic slang? (2) Does it commit to one premise and heighten it? (3) Does at least one line genuinely surprise? (4) Is the humor content-locked (would NOT work on a different article)? (5) Zero AI-isms (no hedging, no meta-commentary, no laugh-track emojis)?
gist_landed (1-5): five binary sub-checks. (1) Does the first sentence contain the quantitative finding (not just the topic)? (2) Could you state the finding from the first two sentences alone? (3) No signposting labels? (4) At least two source-specific details present? (5) Does the opener convey a finding ("27.5% pass rate") rather than a topic ("CMU built a thing")?
I scored the latest agent run against all three.
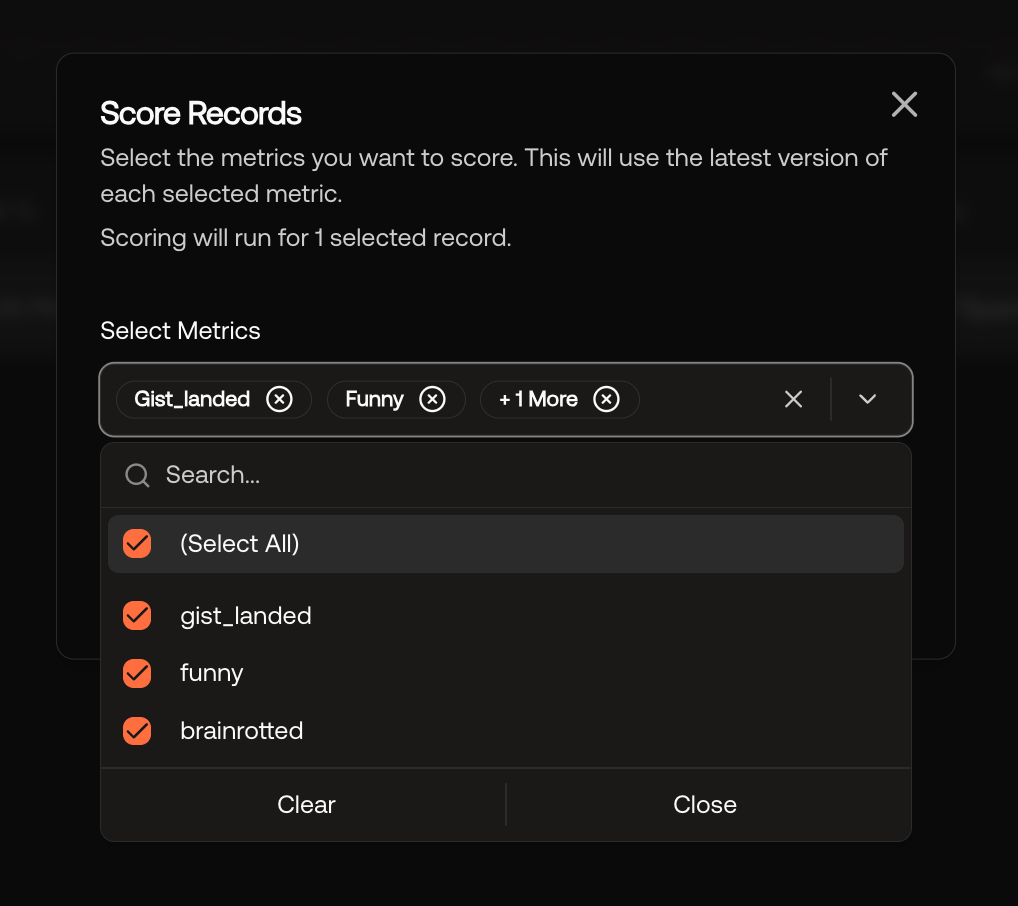
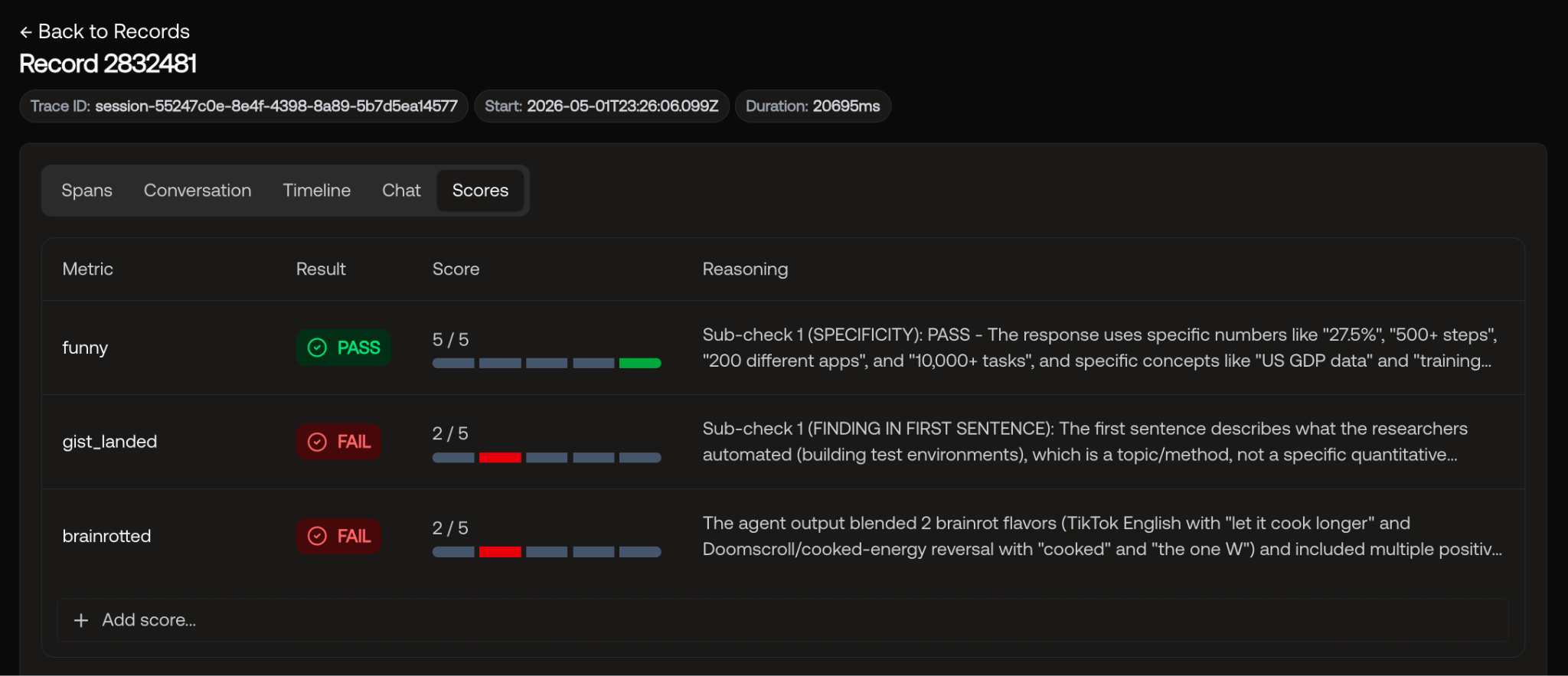
The baseline scores were rough:
- brainrotted failed because the bot was defaulting to one flavor (sigma-grindset style)
- funny scored low because the humor was generic slang-cadence that could apply to any article, not content-locked jokes married to this specific paper’s findings.
- gist_landed failed because the opening sentence was a topic description ("CMU automated testing")
Next, I iterated based on the metrics: I blended brainrot styles in the system prompt, forced the agent to lead with the finding rather than the topic, and utilized source-specific data for comedy instead of generic slang. After two more rounds of iteration and scoring, I ended up with this system prompt as an input for my agent:

And the scores:
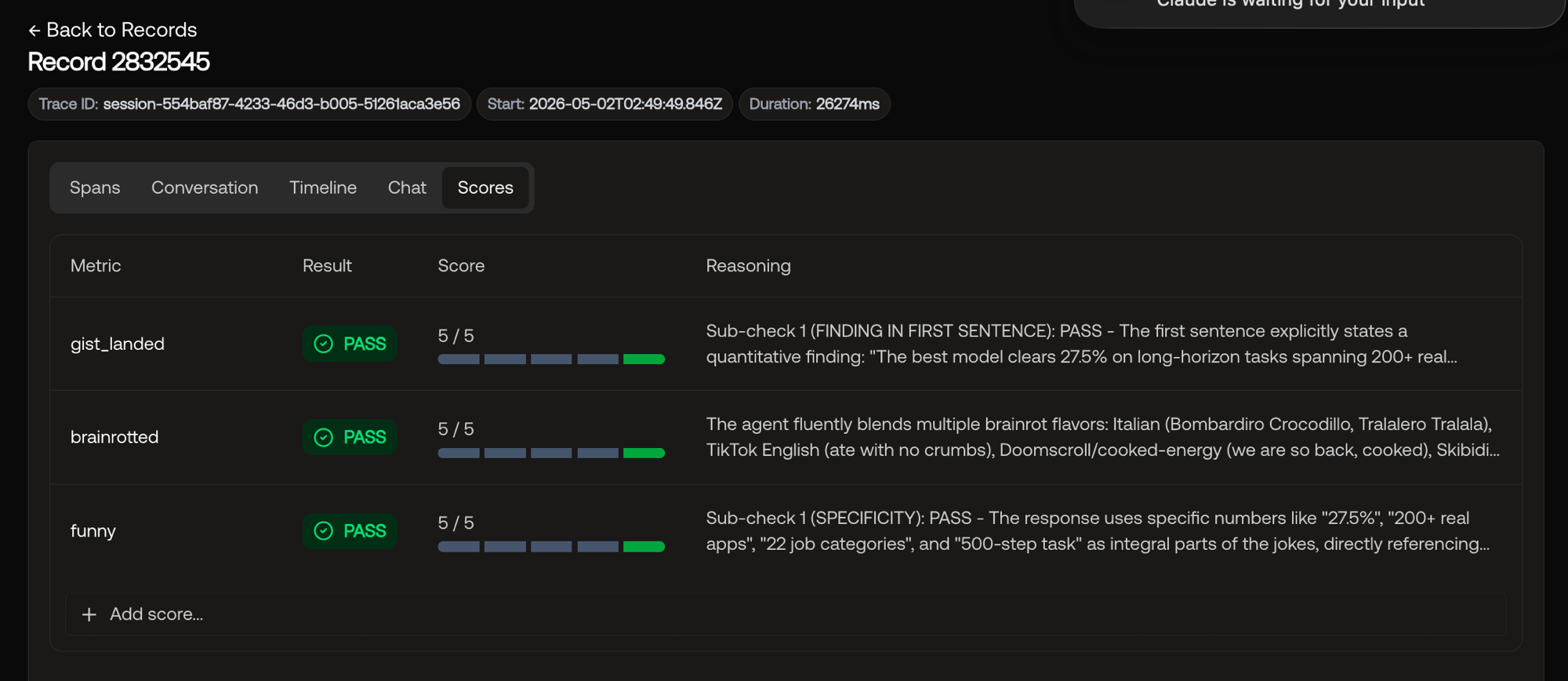
Nice. We noticeably improved the agent with no regressions whatsoever. I’ll actually have more fun learning now, and it’s all because of the overengineered brainrot agent, skibidi-scholar.
Looking forward
Skibidi-scholar is still running. Every time someone drops a link in #random, I run it and get DM sent to me with a brainrotted breakdown and I honestly kind of like it! I'm planning to host it on a server so the agent is automatic, or even let the team vote on outputs so the metrics stay calibrated to what we actually find funny.
Building this was a good reminder that dogfooding your own product on something unserious teaches you things that "real" use cases don't. It is a pain to figure out what taste actually means, write it down, and measure it. That's the hard part of evals, and skibidi-scholar made it fun to learn.
If you want to run the same loop on your own agent, try Scorecard out!