You can’t QA your way to the frontier.
Most AI teams follow the same loop. Ship an agent, collect production logs when users find edge cases, wait for subject-matter experts to review them, fix issues one by one, ship again. Teams call this "evals" but the process is QA, and everyone involved resents it.
AI researchers hate the work because debugging is not innovation. SMEs hate being buried in labeling queues instead of doing high-judgment work. Engineers hate waiting weeks for feedback on every release.
This approach has a ceiling. QA catches regressions. It does not help you add capabilities or get better. And the math gets worse as agents grow more complex: each review takes longer, scenarios multiply, but expert time stays linear. You're doing O(n²) work with O(n) resources.
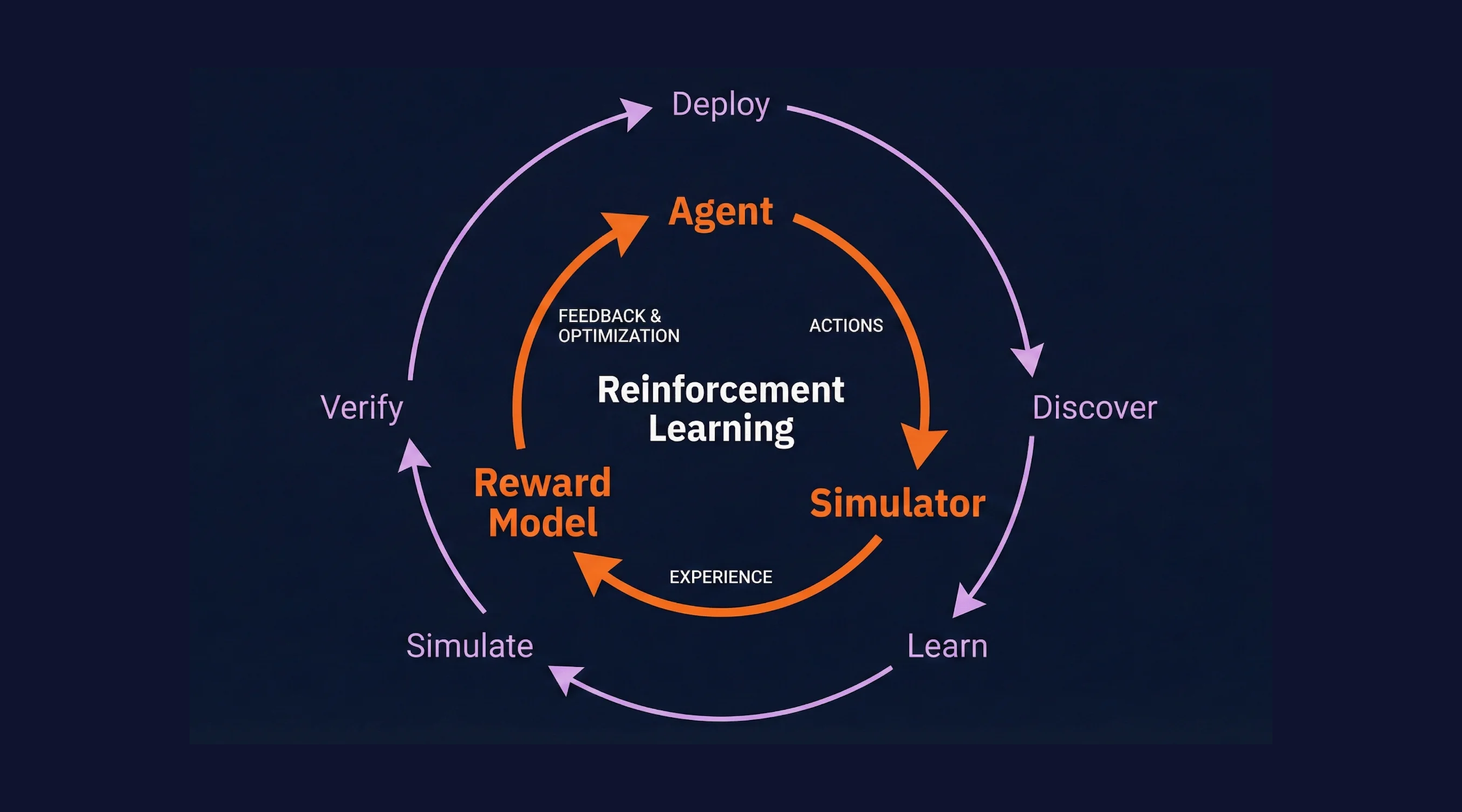
I spent years at Waymo on simulation infrastructure, as the team scaled from dozens of engineers to over 200. Waymo recently published their AI strategy: beyond a capable Driver, you need a realistic Simulator to test against challenging scenarios and a Critic to evaluate performance and identify improvements. All three work together as a flywheel for continuous learning. This framework let Waymo accumulate over 100 million fully autonomous miles while achieving a ten-fold reduction in serious injury crashes compared to human drivers.
Frontier AI labs and the best application teams learned the same lesson. OpenAI's o1 uses large-scale reinforcement learning to teach models how to reason. Cursor trained their Composer model with RL across hundreds of thousands of simulated coding environments. Intercom's AI team describes reasoning and reinforcement learning as the path forward now that scaling pre-training has hit diminishing returns. Epoch AI reports that Anthropic discussed spending over $1 billion on RL environments in the coming year.
Self-improving agents need two things: realistic simulation and encoded expert judgment. You generate messy, edge-case interactions your agent will face instead of replaying production logs. Your SMEs teach a reward model what "good" looks like instead of labeling thousands of cases. The bottleneck shifts from feedback to building.
You don't QA your way to the frontier. You simulate your way there.