
Scorecard announces $3.75M seed funding to revolutionize AI agent testing, enabling developers to run tens of thousands of tests daily and ship trusted AI 100x faster.
All Blogs
Try filtering for other categories.


Auto-improve your agent. Accidentally end up with a team of graders that grade like you would.
I built a bot that turns research papers into brainrot and it sucked. Here's how I fixed it.

Learn how structured, span-level annotations on OpenTelemetry traces create a continuous improvement loop for AI agents — turning human feedback into targeted code fixes via MCP-connected coding assistants.
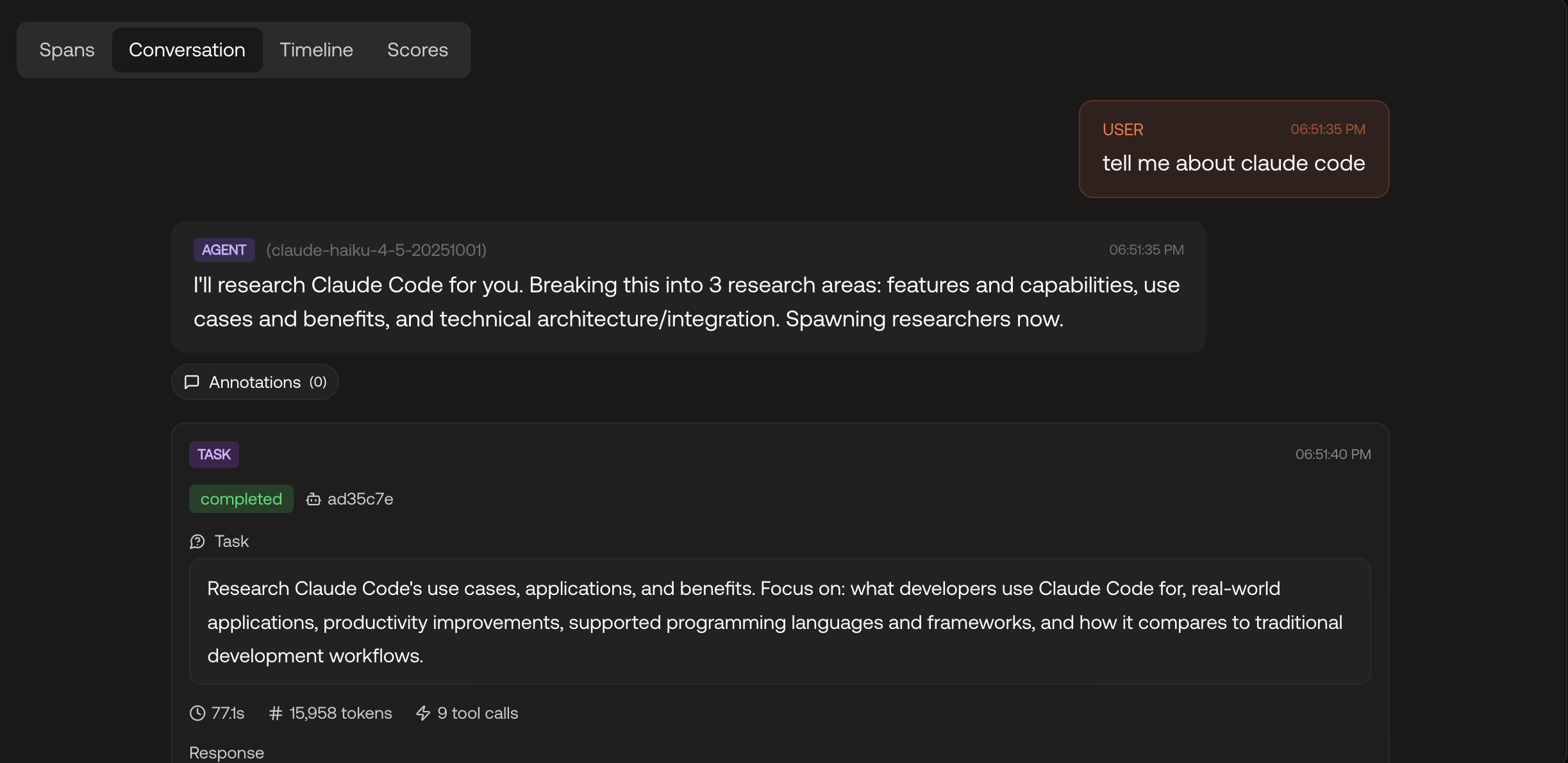
Reveal Anthropic’s hidden reasoning steps in 0 lines of code.
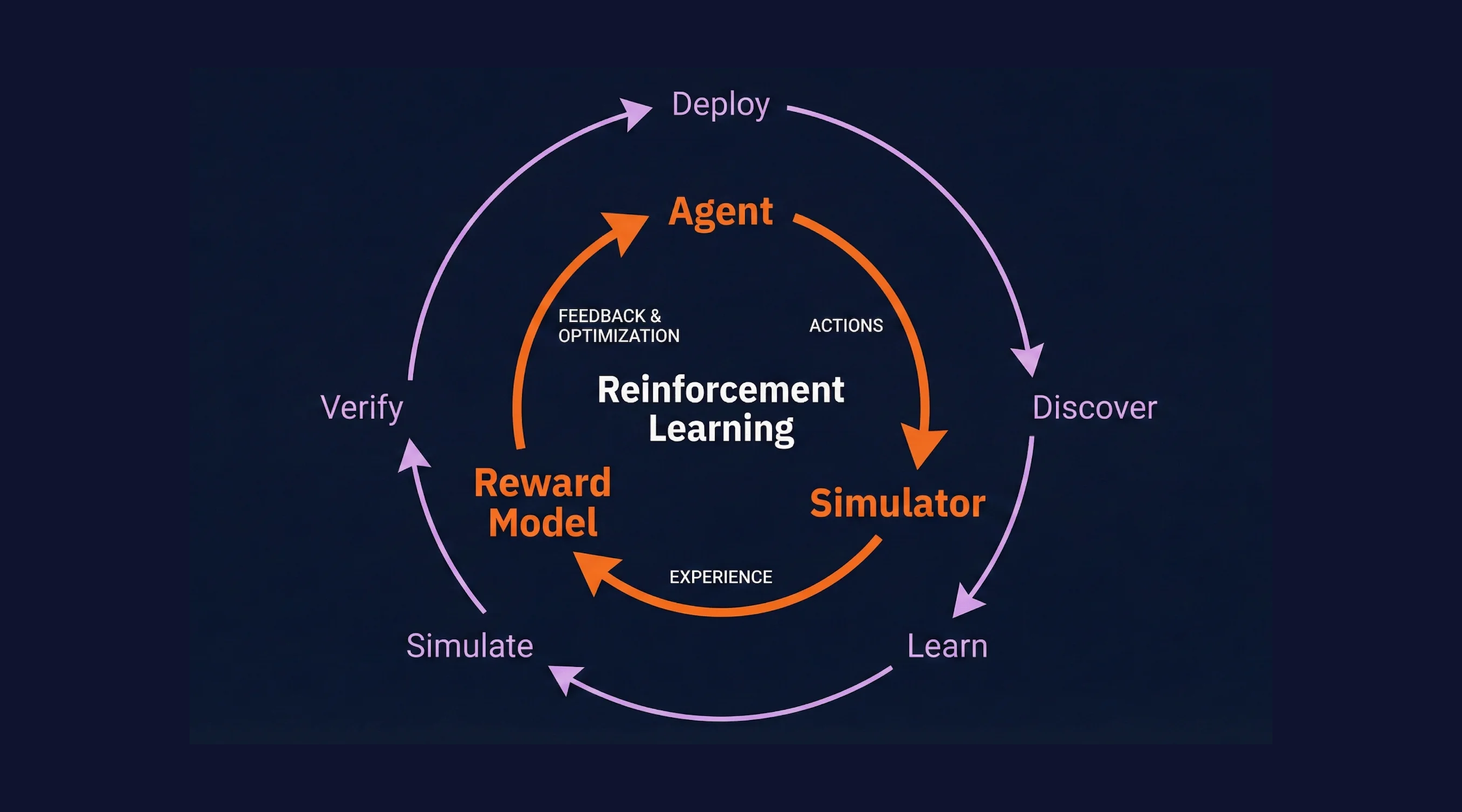
QA finds what's broken. It doesn't help you get better. The best AI teams are shifting from "observe and evaluate" to "simulate and improve." Here's what Waymo, OpenAI, and frontier labs figured out about building self-improving agents.

Introducing AgentEval.org: An Open-Source Benchmarking Initiative for AI Agent Evaluation


Simulations are transforming the development and testing of AI systems across industries, far beyond just self-driving cars.

Unlock the full potential of Large Language Models (LLMs) with a comprehensive evaluation framework. Discover the 5 must-have features to ensure reliable performance and cost-effectiveness in your LLM applications.